Revamping Engagement Models for Digital Business Transformation
Selvakumari Sukumar
December 5, 2024
5 minutes read
Share
Reprocess framework for Snowflake data pipelines
Introduction
Data is of paramount importance for any organization. Thanks to the advent of modern technology, that encompasses processing and storing massive amounts of data at ease. As this data may be diverse and spread across several systems, Altimetrik engineering teams build robust data pipelines to bring the data into a unified data platform, which then helps data analysts, business users, SMEs and executives across the organization for all business and operational needs as a SSOT (Single Source of Truth).
The enterprise data ingested from different upstream systems, may become available at different frequencies owing to the nature of data generated, business units, geographies, latency, operational hours etc. thus resulting in non-availability or delays in data availability for the ETL/ELT pipelines. However, it is critical to efficiently process the data within committed business SLA for the data load pipelines, to make the data available for downstream consumption. Building a data pipeline which has the flexibility of handling such data dependencies, while ensuring data completeness becomes important.
Reprocessing framework provides the flexibility of processing the available data while deferring the processing of missing data at a later point in time when the actual data becomes available. This helps alleviate hard dependencies in data pipeline execution, at the same time build data that is complete and correct at the point in time. The framework is based on a set of rules, which determine whether the data pipeline can continue despite data not being available. This ensures the correctness and completeness of data that is processed to the target system.
Key Benefits:
The framework is developed using Snowflake native javascript procedures.
It utilizes Snowflake’s compute power to perform the checks, so there was no need for provisioning or maintaining additional computes. We could scale it up as per the requirements, complexity and volume of data processed.
The reprocessing was done concurrently across independent objects utilizing the Python libraries for Snowflake.
Enables building a flexible data pipeline, which offers flexibility of handling late arriving data, changes to source data while also logging the history of changes.
Reprocessing Framework
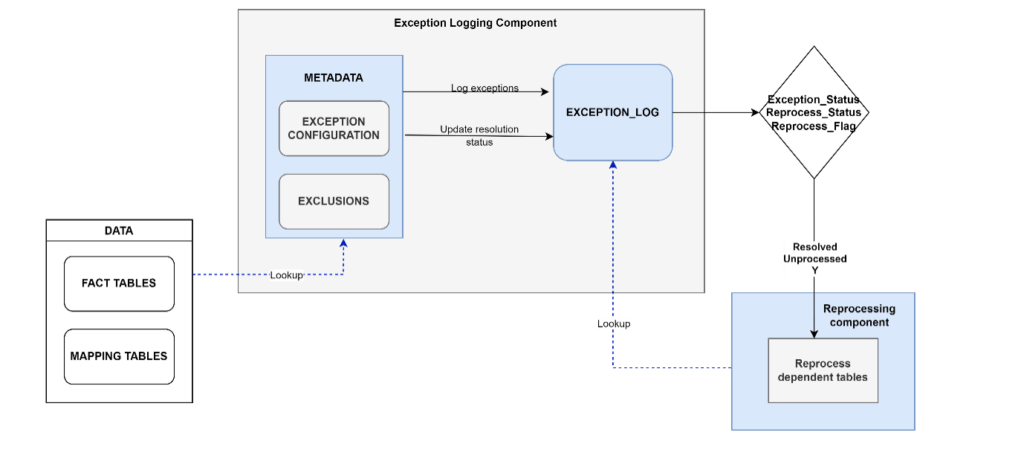
The framework comprises two individual components – (a) Exception Logging Component and (b) Reprocessing Component. The exception logging component identifies and logs exceptions in data. Exceptions may include non-availability of dependent data, changes to master data since last load etc. The exceptions to be captured for each dataset is completely configurable. The Reprocessing Component then reprocesses eligible datasets depending on the type and resolution status of the reported exceptions.
The framework is developed as a configurable and independent piece of code that can be easily pluggable to data pipeline without disturbing any of the existing data mappings. The high-level flow is as follows:
Data ingestion from multiple sources to target.
Run the configured checks on the target data.
Capture exceptions in an exception log (includes missing data and changes made since last load) based on outcome of previous step.
Run the reprocess framework based on the resolution status of reported exceptions.
Features of the Reprocess framework:
Flexibility to allow loading data even while dependent datasets are unavailable, while marking them as exceptions to be tracked for reprocessing.
Adherence to data load SLAs, while ensuring completeness and correctness of data.
Capture the exceptions in an exception log, for traction, reprocessing, auditability and reporting purposes.
Ability to reprocess the exceptions once they are resolved.
Dependencies derived from Snowflake metadata tables.
Flexibility to continue or abort data load based on exception resolution and reprocess status.
Flexibility to add the framework at any point in the data load pipeline.
Extensible and configurable metadata to simplify modification/ addition of exceptions to be checked.
Exception Configuration Metadata
All exception to be captured across different table types are stored in a central metadata table. It is possible that there are different types of exceptions to be reported for the same table. This table is the driver of the Reprocess framework, which is being referred by the Exception log procedure which also acts as the master stored procedure which invokes the respective worker procedure depending upon the type of exception captured.
Structure of this table can vary as per the requirement. Details like Table type, exception type to be run on the table, execution sequence for running exceptions along with audit columns like CREATE_DATE and MODIFIED_DATE are maintained in this table. This can be extended based on specific requirements.
It could happen that certain exception are not applicable for specific tables though they fall under the TABLE_TYPE category configured in the metadata table. To facilitate this, we built an Exclusion table, which holds details of Table names and relevant exceptions that may not be applicable to certain table types.
Exception Logging (Master) Stored Procedure
The master stored procedure is the controller of the Exception logging and Reprocess framework. Using data defined in the configuration tables, it triggers appropriate worker procedures on the respective tables which then capture defined exceptions and logs them into the Exception tables. While newly identified exceptions are logged, these worker procedures also run checks on the data to verify if earlier reported exceptions have been resolved and updates the Exception status accordingly. All resolved exceptions, qualify to be reprocessed.
Exception Logging (Worker) Stored Procedure
The exception types defined in the metadata is executed by a worker that uses an underlying stored procedure. The master procedure orchestrates the sequence of execution.
As an example, the exception type of MISSING_MAPPING is applicable to Mapping and Fact tables in the Datawarehouse. The master procedure calls the corresponding stored procedure SP_EXCEPTION_MISSING_MAPPING procedure. This worker procedure checks the data and logs any new/ resolved exception in the Exception Log table. The Exception Log table has details such as Exception Type, Table Name, Exception Status, Reprocess Status, Reprocess Flag etc. This can be extended based on specific requirements.
During subsequent runs, all reported exceptions are verified for resolutions and the resolution status is updated accordingly in the Exception Log. All exceptions, where the EXCEPTION_STATUS=’Resolved’ and REPROCESS_STATUS = and REPROCESS_FLAG = ‘Y’, qualify for reprocessing.
Addition/ Exclusion of Rules
The framework facilitates easy extensibility. Adding new rule or code is quite easy. A new stored procedure needs to be created with the rule execution logic and the same needs to be configured in the metadata table. The exclusion of checks is also facilitated by adding an entry in the EXCLUSION_TABLE. All tables that are part of the EXCLUSION_TABLE will not be considered for Exception reporting and reprocessing framework.
Reprocess dependent tables
Based on the exceptions captured, the dependent tables, are reprocessed. The dependencies are set by defining referential integrity constraints in the Snowflake database. This enables easy management of data dependencies.
As an example, for an exception resolved in the CUSTOMER_MAPPING table, the data in the dependent fact tables and reporting tables are reprocessed. Below is an image of the exception log table, which has rows qualified for reprocessing.
All tables that have a referential integrity defined on Customer_Mapping table gets reprocessed. This can be easily derived from the Snowflake owned metadata tables namely REFERENTIAL_CONSTRAINTS and TABLE_CONSTRAINTS. Once all the master data sets are loaded and exception logs have been updated, the Reprocessing Framework is invoked as an individual component. Type of reprocessing e.g., upserts, appends, truncate and load etc depends on the data load strategy of respective tables. In our case, the Fact Tables and tables created for consumption by downstream reporting applications were reprocessed with upserts. This may vary depending upon the business use case, type of data being processed, and load strategies defined in the data load pipeline.
All exception types defined in the metadata are captured from respective datasets and logged in the Exception_Log. It was shared with business for analysis and further actions.
Conclusion
The implementation of the Exception handling and Reprocessing requirements via framework enabled the data loads to be done seamlessly and flexibly. The framework is completely configurable and extensible, thereby making it easy to handle any new changes to existing rules, while also significantly improving the productivity. Being able to process data loads, eliminating hard dependencies and processing data loads in parallel, resulted in reduced pipeline execution times.
Altimetrik is committed to protecting your personal information. To apply for a position, you will need to provide your email address and create a login. Your information will be used in accordance with applicable data privacy laws, our Privacy Policy, and our Privacy Notice.